Einstieg in Kubernetes (1/5)

tl;dr; Docker-Container erleichtern die Implementierung von Microservice-Architekturen und stoßen einen revolutionären Wandel in der Softwareentwicklung an.
- Warum Entwickler Isolation lieben
- Das Schwergewicht: Virtuelle Maschinen
- Ressourcenschonend: Docker-Container
- Teile und Herrsche
- Ein Orchester aus Containern
Warum Entwickler Isolation lieben
Wird etwa eine Web-Applikation entwickelt, also ein Computerprogramm, das später über einen Browser abgerufen werden kann, ist es entscheidend, möglichst fehlerfreien Code zu erzeugen und gleichzeitig die technische Konfiguration, unter der das Programm später produktiv betrieben werden soll, zu berücksichtigen.
Die Entwickler arbeiten in der Regel auf einem „normalen“ Heimcomputer, einem PC oder Laptop oder eventuell sogar auf einem Tablet. Bereitgestellt wird die Web-Applikation jedoch über einen Server. Dieser ist speziell für diese Art von Einsatz optimiert und meist leistungsstärker als ein PC.
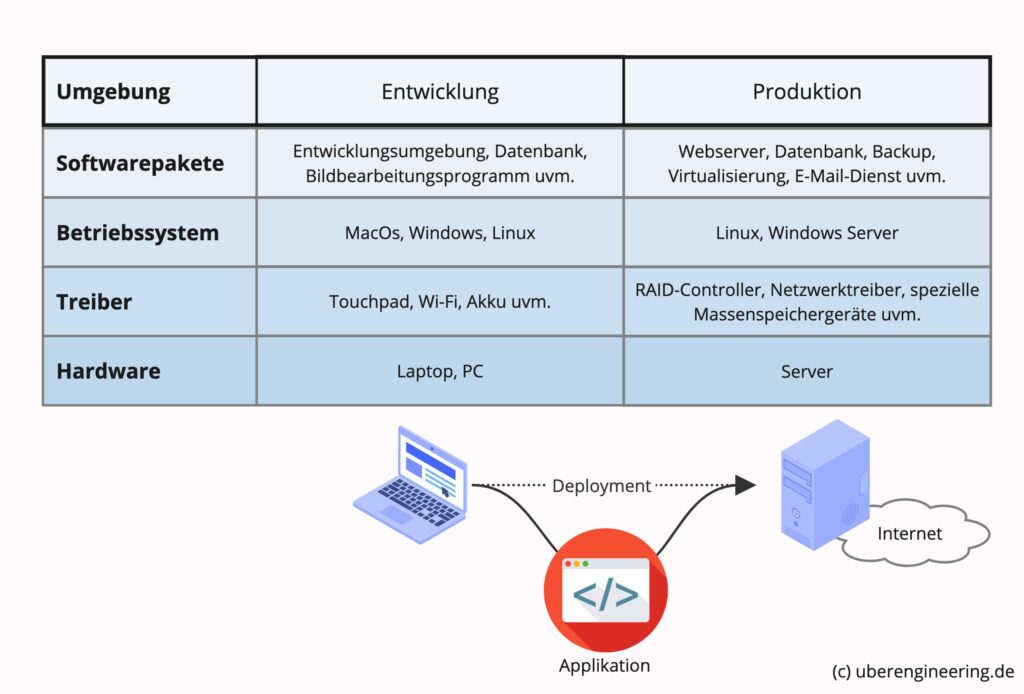
Ein solcher Server hat ein gänzlich anderes Einsatzgebiet als ein PC, daher unterscheidet er sich maßgeblich in der verbauten Hardware und der Software, die auf ihm läuft. In einem einfachen Szenario weiß jeder Entwickler im Vorhinein, wie der Server konfiguriert ist. Demnach könnte er seinen Computer, auf dem er entwickelt, vergleichbar konfigurieren. Sobald die entsprechenden Softwarepakete installiert sind, wäre sicher, dass sich die Web-Applikation auf seinem Computer und dem Server gleich verhält.
Im Gegensatz dazu unterscheiden sich in der Realität der Computer des Entwicklers und der Server drastisch. Eventuell existieren gar keine identischen Softwarepakete für Server und PC. Softwarevarianten für unterschiedliche Betriebssysteme zeigen außerdem durchaus abweichendes Verhalten.
Und in der Regel wird an mehreren Projekten parallel gearbeitet. Diese werden später auf ganz unterschiedlichen Servern laufen. Folglich gestaltet sich das projektbezogene Umkonfigurieren äußerst umständlich. Lösbar wird das erst, wenn jedes Projekt in einer isolierten Umgebung mit einer eigenen Konfiguration laufen kann.
Das Schwergewicht: Virtuelle Maschinen
Ein eigener Computer für jedes Projekt könnte das Problem lösen, ist aus naheliegenden Gründen jedoch äußerst unpraktisch. Günstiger ist es, die isolierten Umgebungen mithilfe von Software zu erzeugen. Dies bedeutet allerdings, dass ein Computer zwei Betriebssysteme parallel ausführen muss. Das eigentliche Betriebssystem – in diesem Zusammenhang als „Host-System“ bezeichnet – und das Zweite, welches die Konfiguration des Servers abbildet. Dieses zweite Betriebssystem ist „nur“ eine virtuelle Version des Servers, da die Hardware des Host-Systems natürlich die gleiche bleibt.
Die Idee der Virtualisierung gab es schon in den 1960er-Jahren bei IBM. Dort wurden mehrere Betriebssysteme auf jeweils einem Großrechner ausgeführt. Erst deutlich später in den 90ern wurde die Virtualisierung auch bei PCs populär. Zu diesem Zeitpunkt kamen VMware und VirtualBox auf den Markt, Software zum Betreiben virtueller Betriebssysteme.
Ein ganzes Betriebssystem zu emulieren ist ein aufwändiger Prozess, der viel Rechenleistung erfordert. Daher forderte das Arbeiten auf virtualisierten Betriebssystemen einiges an Geduld, schließlich liefen sie deutlich langsamer als das Host-System.
Die gängige Bezeichnung „Virtuelle Maschine“ (VM) lässt schon eine gewisse Behäbigkeit erahnen. Erst als 2005 Intel und AMD begannen, Virtualisierung hardwareseitig zu unterstützen und als Mehrkernprozessoren Einzug in die heimischen PCs fanden, konnten die virtuellen Maschinen in einer akzeptablen Geschwindigkeit ausgeführt werden.
Damit war zwar das Problem der isolierten Umgebung gelöst, jedoch blieb angesichts der Schwerfälligkeit ein fader Beigeschmack.
Ressourcenschonend: Docker-Container
Bisweilen gibt es diese Gänsehautmomente, in denen einem bewusst wird, auf etwas gestoßen zu sein, das alles verändern wird. Ich hatte solch einen Moment beim Lesen des Bitcoin-Whitepapers und als ich das erste Mal einen Docker-Container auf meinem Laptop ausführte.
Das Docker-Projekt wurde 2013 von Solomon Hykes als Open-Source-Projekt innerhalb der Firma dotCloud, einem Platform-as-a-Service (PaaS)-Unternehmen, gestartet. Die Idee war, eine bessere Containerisierungsplattform zu schaffen, die es erleichtern würde, Anwendungen in verschiedenen Umgebungen zu entwickeln, zu implementieren und auszuführen.
Docker baut auf bestehenden Linux-Technologien auf, macht sie jedoch durch eine benutzerfreundlichere Schnittstelle zugänglicher und verwaltbarer. Starten lassen sich Docker-Container innerhalb weniger Sekunden, und auch auf einem normalen Laptop lassen sich problemlos mehrere Container gleichzeitig ausführen.
Ein weiterer Vorteil von Docker ist seine Portabilität: Einmal erstellte Container können einfach auf anderen Systemen ausgeführt werden, solange diese ebenfalls über einen Docker-Host verfügen. Währen eine VM oft mehrere Gigabyte groß ist, kann ein Docker-Container mit wenigen Megabyte auskommen.
Das erleichtert das Deployment – also das Übertragen der programmierten Anwendung auf den Server – enorm. Das Docker-Projekt gewann schnell an Fahrt und zog eine große Entwicklergemeinschaft an, was zur Ausgründung als eigenständiges Unternehmen führte.
Der Erfolg von Docker markierte auch eine Veränderung in der Softwarebranche hin zu Mikrodienst-Architekturen, und revolutionierte die Art und Weise, wie Anwendungen entwickelt, ausgeliefert und betrieben werden.
Teile und Herrsche
Jetzt war es möglich, jedes Projekt isoliert in einem eigenen Docker-Container zu entwickeln. Der Programmcode und alle notwendigen Pakete wurden direkt in den jeweiligen Container installiert. Einmal auf einem Docker-fähigen Server übertragen, lief die Anwendung exakt wie in der Entwicklungsumgebung.
Dieses brachte viele Vorteile mit sich. Zum Beispiel, wenn ein Projekt eine spezielle Version einer Datenbank benötigte oder der Kunde die Entwicklung in einer exotischen Programmiersprache wünschte. Die Installation in einem Container barg keinerlei Risiken – ein hörbares Aufatmen ging durch die Reihen von Server-Administratoren und Entwicklern.
Zudem entstanden bei GitHub und Co. immer mehr Projekte, in denen Anwendungen in Docker-Container gepackt wurden. Da schon ein Docker-Container von 5 MB ein komplettes Linux abbilden kann, waren die Container klein genug, um eine Mentalität des „Eine Anwendung pro Container“ zu etablieren. Die Vorteile im täglichen Einsatz überwogen das bisschen Overhead bei Weitem.
In der Softwarearchitektur gab es schon lange das Konzept von Microservices. Ein Microservice ist ein kleiner, eigenständiger und unabhängiger Teil einer Softwareanwendung, der eine bestimmte Aufgabe erfüllt und über eine programmatische Schnittstelle (API) zugänglich ist.
Genau dieses ließ sich jetzt einwandfrei mit Docker-Containern realisieren. Ganz im Sinne einer „serviceorientierten Softwarearchitektur (SOA)“. Docker lieferte das Werkzeug, um mit wenigen Zeilen per Copy&Paste beliebige Dienste zu komplexen Softwareanwendungen zu verknüpfen.
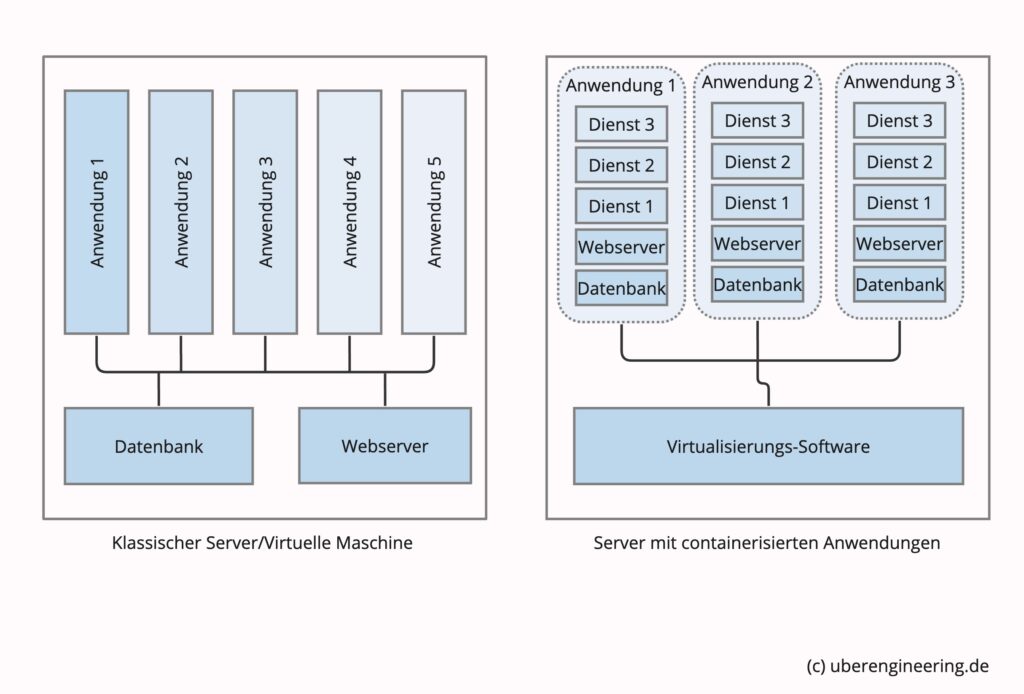
Angenommen, nachdem die neue Web-Applikation in den produktiven Betrieb übergegangen ist, stellt sich heraus, dass ein bestimmter Vorgang immer wieder hakt und Verärgerung bei den Endkunden hervorruft. Ein wenig Profiling zeigt, dass die Ursache das Einfügen eines Wasserzeichens in die vom Kunden hochgeladenen Bilder sind.
Ist ebendieser Prozess in Form eine Microservices in die Architektur integriert, können explizit dessen Ressourcen erhöht werden, oder der Algorithmus wird überarbeitet, oder es wird eine gänzlich andere Bibliothek eingesetzt – alles ohne den Rest der Applikation anfassen zu müssen. Die Vorteile liegen auf der Hand: Eine höhere Flexibilität, Skalierbarkeit und eine bessere Wartbarkeit der Anwendungen. Microservices sind somit ein wichtiger Baustein für die Zukunft der Softwareentwicklung.
Ein Orchester aus Containern
So viele Möglichkeiten bringen natürlich auch Herausforderungen mit sich. Wie verwaltet man dutzende Container? Wie tauscht man die einzelnen Container am besten im laufenden Betrieb aus? Was tun, wenn ein Container abstürzt? Wie lässt sich das Skalieren einzelner Microservices automatisieren? Wie sichert man den Zugriff auf einen Microservice ab?
Zu Beginn habe ich all das manuell und mit der Hilfe vieler Skripte versucht, mit Docker Swarm, Portainer und Rancher. Doch blieb immer der Eindruck, dass es auch eleganter und effizienter gehen müsste. Und dann stieß ich auf Kubernetes.
Das Arrangieren einer Symphonie auf die verschiedenen Instrumente eines Orchesters wird „orchestrieren“ genannt. Dieser Begriff wurde auf die Welt der Container übertragen. Um ein Orchester aus Containern zu schaffen, bedarf es einer orchestrierenden Instanz – einem sogenannten Container-Orchestrierungs-Framework.
Dieses kümmert sich um die automatische Skalierung einzelner Services, den Austausch fehlerhafter Container sowie um das Load-Balancing zwischen den verschiedenen Instanzen. Es arrangiert die Komponenten einer Anwendung, verwaltet die Infrastruktur, verteilt die Ressourcen und überwacht den Betrieb jedes einzelnen Containers.
Genau diese Aufgaben vereint Kubernetes und liefert dazu ein umfassendes Konzept zur Konfiguration jeder einzelnen Komponente.
Die Geschichte der Entwicklung von Kubernetes begann bei Google im Jahr 2014. Ursprünglich wurde es als internes Projekt namens „Borg“ entwickelt, um die Verwaltung und Orchestrierung von Containern für ihre eigenen Anwendungen und Ressourcen effizienter zu gestalten. Aufgrund des gestiegenen Interesses an Containertechnologie und der wachsenden Community um Docker entschied sich Google, eine Open-Source-Version von Borg zu entwickeln.
Diese wurde schließlich als Kubernetes (auch als „K8s“ abgekürzt) bekannt und im Jahr 2015 der Öffentlichkeit vorgestellt. Seitdem hat sich Kubernetes zu einer der führenden Plattformen für die Orchestrierung von Containern entwickelt und wird aktiv von einer großen und vielfältigen Community weiterentwickelt. Die rasche Akzeptanz von Kubernetes hat zu einer Vielzahl anderer Open-Source-Tools geführt, die darauf aufbauen und das Kubernetes-Ökosystem weiterentwickeln.
Schreibe einen Kommentar